
就面前,GitHub依然能齐全看到马斯克开源的保举算法系统了。
开源文献里明确示意,这是一个险些统统由AI模子驱动的算法系统。
咱们移除了所有这个词东说念主工设想特征和绝大多数启发式章程。
讯息一出,通盘社区坐窝怡悦了,最高赞上去即是一顿猛夸:
incredible!莫得其他平台能作念到如斯透明。

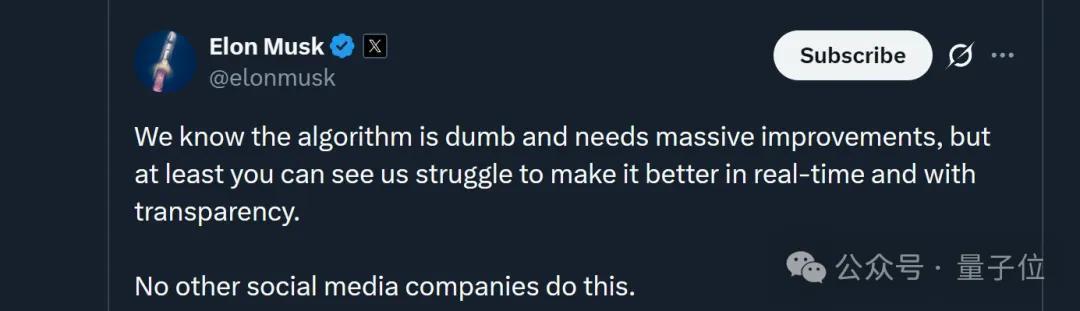
马斯克本东说念主也火速转发了工程团队原帖,不外一向言辞高调的老马,此番却低调示意:
咱们知说念这个算法很蠢(dumb),需要大幅纠正,但至少您不错及时、透明地看到咱们为纠正它而致力。
其他外交媒体公司齐莫得这么作念。
早在2022年收购(原Twitter)之前,马斯克就屡次月旦该平台过于紧闭。
自收购之后,他也杀青原意屡次公开Twitter中枢保举算法,这一次也算是不忘初心了。
原本纯AI驱动的保举系统,是这么运作的!话未几说,咱这就扒一扒整套系统的运作机制。
一句话概述这个系统即为:
基于Grok-1同款Transformer架构打造,能通过学习你的历史互动行为(点赞/回报/转发过什么),来决定给你保举什么内容。
从用户掀开“For You”运转,客户端会向办事器发送一个肯求,触发通策划法过程。
然后系统会先作念一件事——搞了了你是谁、你最近在干什么、你平常对什么内容有反应。
为实现这一见识,系统会拉取两类用户信息:
行为序列(Action Sequence):一类代表最径直、最历害的兴致信号,比如最近点赞、回报、转发、点进、停留过什么。属性(Features):另一类代表弥远属性,比如情态列表、声明的兴致主题、地舆位置、使用确立等。这一步的见识并不是东说念主工构造特征,而是尽可能信得过地构建“及时用户画像”——
以前工程师可能会假定“某些属性很焦灼”,然后手动编写章程或公式去诡计一个“用户兴致得分”。
但这实质上是工程师的猜思,而非用户信得过状况的响应。
于是马斯克的这套算法就决定不作念任何预设假定,而是尽可能多地、原始地汇集用户最信得过的行为反应,然后将这堆数据径直喂给后续的模子,从而让模子我方去从原始数据中学习和发现规章。(即“去东说念主工化”和“端到端”)
而拿到及时用户画像后,系统会接着兵分两路,从通盘平台的海量推文中快速筛选出几千条“可能关联”的推文。
一条是通过熟东说念主圈。即从Thunder模块,径直握取你情态的所有这个词东说念主的最新推文。
另一条是通过外部。愚弄Phoenix Retrieval这一中枢检索模块,握取那些你可能感兴致、但来自未情态账号的推文。
以上两类着手不同的信息,会在后续阶段被长入对待。
需要提示,此时筛选出来的还仅仅推文ID。
于是系统贯通过Hydration模块,补全每条候选推文的信息,包括推文全文、作家细目、图片/视频、历史互动数据等,以便后续深度评估。
何况在负责运转诡计前,还会进一步通过Filtering模块淘汰那些显著不要的内容,举例:
重迭或落伍的帖子用户我方发布的内容来自拉黑或静音账号的帖子包含用户屏蔽要津词的内容依然看过或在现时会话中展示过的帖子用户无权限打听的订阅内容记取,这一步只作念一件事:回答某条内容“能不成出现,而不是值不值得保举”。
铺垫到这里,最终剩下来的内容会被逐条送入Phoenix排序模子进行打分。
这个模子是一个基于Transformer的模子,它会同期罗致:
用户的行为序列与属性信息单条候选帖子的内容与作家信息然后模子会瞻望用户对某条推文履行种种操作的概率,并将种种概率按照预设权重进行加权组合(如点赞类正向行为加分、拉黑类负向行为减分),并变成最终排序分数。
基于此,系统还会进行极少工程层面的诊疗——
比如界限作家种种性,幸免单一账号在信息流中占据过高比例(小心某一大V刷屏)。
这里也需要提示,为了保证送入的每条帖子齐是寂寞评分的,是以系统还有利竖立了“不允许候选帖子互相看见”(推文之间莫得交叉看重力机制)。
所有这个词候选帖子按最终得分排序,系统从中选出Top-K条帖子,看成本次肯求的保举终局。
何况在复返客户端之前,系统还会进行临了一轮校验,确保内容相宜平台安全模范——
举例,移除任何已删除、被象征为垃圾信息或包含暴力血腥等非法内容的推文。
最终,资格重重筛选后的信息会凭证分数上下,范例展示给客户端用户。
讲究下来,这套系统有时得胜运转的五苟简津在于(官方划要点版):
(1)纯数据驱动,拒却东说念主工章程。
透顶摒弃东说念主工界说“什么内容算好”的复杂章程,改由AI模子径直从原始用户数据中学习。
(2)遴荐候选休止机制,寂寞评分。
AI模子在给内容打分时,每条内容“看不见”其他候选内容,只可看到用户信息。这确保了每条帖子的分数不会因为同批次其他帖子而变化,分数一致且可高效缓存复用。
(3)哈希镶嵌,实现高效检索。
检索和排序齐使用多个哈希函数进行向量镶嵌查找,提拔成果。
(4)瞻望多元行为,而非单一分数。
AI模子不径直输出一个笼统的“保举值”,而是对多种用户行为同期瞻望。
(5)模块化活水线,撑持快速迭代。
通盘保举系统遴荐模块化设想,各个组件不错寂寞开荒、测试、替换。
“是的,这算法太烂了”不外,固然世东说念主对老马开源的姿态抒发了歌咏,但奈何这套算法如故有一些“颓势”。
有网友就在保举算法开源后吐槽说念:
由于API打听受限且资本昂贵,面前屏蔽列表的作念法依然很罕有了,但以前这种作念法极度广漠。
算法必须让较旧的屏蔽列表跟着时刻推移而逐渐隐没,这么这些较旧的屏蔽列表就不会再被坏心愚弄。
言下之意是,算法代码表露“被无数用户屏蔽”是一个强负面信号,会径直导致账号被“降权”,即内容更难取得保举,但代码中莫得明确看到针对“屏蔽”信号的时刻衰减机制。
这意味着,历史上的屏蔽纪录可能于今仍在影响账号的保举分数。
此番言论也引得马斯克本东说念主现身驳斥区吐槽:
是的,这算法太烂了。
但非论怎样,老马思要改革的魄力依然明确——
不仅往日开源、面前开源,何况接下来还会赓续开源,改日每4周将重迭一次开源更新。
开源仓库:
https://github.com/xai-org/x-algorithm— 完 —
量子位 QbitAI
情态咱们开yun体育网,第一时刻获知前沿科技动态